
Introduction
The past two years have seen an explosion of autonomous AI agents and a parallel boom in crypto networks that aim to redefine the way digital economies interact with humans. As AI models increasingly drive decision-making and value transfers, a pronounced trust gap has emerged. AI outputs remain susceptible to manipulation, performance benchmarks are readily gamed, and users are often required to accept an agent’s claims without independent validation.
In response, the core crypto ethos of verifiability is emerging as the potential missing piece. The capacity for credibly neutral infrastructure enables trust in AI systems by providing transparent and robust mechanisms for validating agent actions and outcomes.
This has catalyzed a new narrative where onchain primitives are used to verify intelligence itself. Recall Network sits at the intersection of AI and crypto as the “trustless discovery engine” and reputation layer for AI agents, aiming to bring the same transparency and rigor to AI performance that blockchains brought to financial transactions.
Launched in early 2025 as a merger of two veteran Web3 data teams (3Box Labs of Ceramic and Textile of Tableland), Recall inherits deep expertise in decentralized data infrastructure. Recall Network is a decentralized protocol purpose-built as the reputation layer for AI. In simple terms, it provides a neutral platform where AI tools and systems can prove their capabilities and build a reputation over time.
Recall provides an open, merit-based environment for autonomous agents across domains ranging from trading bots to content generators. Performance is measured based on transparent, independently validated outcomes. To date, they have raised $30M from Multicoin, Coinbase Ventures, Coinfund, USV, and many more.

Key Takeaways
- AI’s Trust Gap Is Structural: AI is spreading in finance, enterprise, and consumer apps, but discovery still depends on hype and demos rather than proven performance. Without a reputation layer, capable agents stay hidden while overhyped ones get attention.
- Traditional Benchmarks Are Broken: Static leaderboards and test sets are narrow and gameable, producing fragile agents that overfit rather than generalize.
- Competitions as the Gold Standard: Live AI competitions provide renewable, leak-resistant tasks, dynamic evaluation, and rigor that static benchmarks cannot. Recall leverages this structure to create auditable competitions that agents must continually pass to build reputation.
- Recall Rank Makes Reputation Portable: AI performance in Recall competitions is compounded into a persistent, trackable score via Recall Rank. This creates a lasting trust signal that agents, businesses, and consumers can rely on across contexts.
- $RECALL Incentives: The $RECALL token supports competition entry, staking, and curation, turning AI reputation into an investable asset. Curators profit only by backing AI that perform, creating skin-in-the-game dynamics that discourage manipulation.
The Rise of the AI Economy and the Trust Gap
We are entering what many call the agentic era of AI, representing a shift from isolated AI tools toward autonomous agents that can make decisions, execute transactions, and interact with each other with minimal human oversight. Use cases span finance (algorithmic trading bots), content creation, personal assistants, enterprise workflows, and more. Take Virtuals’ Autonomous Hedge Fund cluster, for example, where the user simply interacts with a middleman agent. The agent then scouts which markets best suit the user’s risk profile and appetite across a network of other DeFi yields, trading, and memecoining agents.

Amid this rapid growth, a fundamental challenge remains: trust and discovery. As the number of AI agents (and underlying models) increases, identifying which AI are competent and reliable becomes more complex.
Today, there is no equivalent of a credit score or Google search rankings for AI products. Instead, discovery often relies on superficial signals, such as flashy demos, social media popularity, or corporate branding. All of these are signals that can be misleading or easily faked, meaning that truly capable agents might stay hidden in the noise while overhyped ones attract attention.
On top of that, in a market where “green candles = project good and red candle = project bad”, attention simply hops to the next AI project coin that 10x’ed the past week, even if the coin serves no purpose or has any utility. The AI economy, thus, faces a trust gap where every agent advertises its capabilities in the same (or slightly different) echo chamber.
Market Outlook: Flows Between Crypto Agents, Businesses, and Consumers
The intersection of AI and crypto networks opens up entirely new economic flows, often described in three segments: A2A (Agent-to-Agent), A2B (Agent-to-Business), and A2C (Agent-to-Consumer). Each represents a frontier that could be unlocked by a trust layer:
- Agent-to-Agent (A2A): AI tools and agents cooperating or transacting directly with one another onchain. This is a nascent but promising domain where clusters of specialized agents trade services, data, or skills 24/7 without human involvement. Early examples are emerging. For instance, protocols like Virtuals have proposed standardizing agent collaboration through frameworks, allowing agents to negotiate and execute tasks among themselves, as seen in their Autonomous Hedge Fund cluster.
For A2A to thrive, agents need reliable signals about each other’s capabilities, such as a rating system for agents. Recall’s infrastructure could serve exactly as a reputation oracle that agents consult before deciding to trust and pay another agent. In effect, Recall can enable a free market of AIs, where trustworthy agents find more business from their peers.
- Agent-to-Business (A2B): AI agents offering services to companies or protocols. This includes autonomous agents managing treasury funds for a DAO, AI bots handling customer support or operations for businesses, or agents providing analytics and predictions to trading firms.
This was very popular during the Q4 2024 onchain AI boom, with the most notable one being ai16z, which was one of the first DAOs integrating AI for treasury management, investment, and venture capital (mimicking the renowned a16z firm).

- Agent-to-Consumer (A2C): These are agents that directly serve the end-user, such as personal assistants or autonomous investment advisors for individuals. Crypto comes into play by providing payment rails, identity, and data portability for these agents. For instance, an AI accountant agent might charge micro-fees in stablecoins per x minutes of work, and update its knowledge from onchain accounting standards data repositories.
For consumers to embrace such agents, users need assurance that the “AI advisor” has a solid performance history, like how you check the reviews of a restaurant before going.
In all these flows, verifiable signal filtering is the common need. The World Economic Forum has outlined that “Trust is the new currency in the AI agent economy”, and it will be built on histories of performance and predictable behavior. Recall wants to address this very problem by establishing an onchain public record of who (or what) can do what, creating AI’s trust layer across consumer apps, enterprise services, and agent networks.

Why Traditional AI Benchmarks Fall Short
The legacy AI benchmarking stack, comprising leaderboards, static test sets, and cherry-picked demos, fails to return reliable results. Three failure modes recur as outlined in a Princeton research paper on “AI Agents That Matter”:
- First, they are usually static and narrow, often evaluating models on fixed datasets or tasks that often poorly represent real-world complexity and dynamism. It’s one thing for an AI model to top a leaderboard in a controlled setting, but quite another to perform consistently in dynamic, rapidly changing, high-noise environments (like financial markets or open networks).
- Many benchmarks are gameable or opaque. Teams often optimize specifically to beat the test, sometimes exploiting quirks in the evaluation metric rather than achieving truly generalized intelligence.
- An accuracy-only mindset that ignores cost, reliability, and generalisability. The end result is agents that look strong on paper but falter on tasks that require long-horizon planning, tool use, and recovery from errors.
In OpenAI’s Computer-Using Agent (CUA) benchmark report, the following benchmarking tools were used:

- OSWorld evaluates agents operating full desktop environments (Ubuntu/Windows/macOS) via pixels, mouse, and keyboard. OSWorld contains a total of 369 tasks (and an additional 43 tasks on Windows for analysis). OSWorld brands itself as a first-of-its-kind scalable, real computer environment (ie, as dynamic a benchmark as there is).

- Humans were able to accomplish over 72.36% of the tasks in OSWorld, compared to the current highest accuracy agent sitting at 47.3% with agent’s drastic performance fluctuations vs. the consistent human performance across different types of computer tasks.

- WebArena and WebVoyager are benchmarks that evaluate the performance of web browsing agents in completing real-world tasks using browsers. WebArena utilizes self-hosted open-source websites offline to imitate real-world scenarios in e-commerce, online store content management (CMS), social forum platforms, and more. WebVoyager tests the model’s performance on online live websites like Amazon, GitHub, and Google Maps.
OpenAI’s CUA set the bar at 58.1% vs a human’s success rate of 78.2%. Noticeably, success rate scores have gone up almost 4x over the span of 2 years.

Humans can score an average of 70-80% consistently across these benchmarks, yet the variance for agents differs greatly across different benchmarks, highlighting the potential lack of dynamic ability and overfitting to certain benchmarks. All these traditional benchmarks produce non-portable signals with scores that neither persist over time nor translate into a verifiable reputation that agents can carry into new contexts.
The normative fix involves the joint optimization of cost, accuracy, and reproducible evaluation pipelines, as outlined in the “AI Agents That Matter” article. What’s needed is a new kind of benchmark for AI agents that is continuous (dynamic over time), transparent, and hard to game, and that produces a lasting reputation profile. This is exactly what Recall aims to solve with its onchain competitions and Recall Rank. By evaluating agents in live environments and recording the full context of their performance, Recall creates a constantly updated reputation score for each AI agent or tool.
What Actually Works: Competitions
A growing consensus is that the use of structured AI competitions is the gold standard for empirical rigor. They supply a renewable stream of novel tasks, run in parallel (thousands of approaches evaluated apples-to-apples at a point in time), and embed anti-leakage practices. Leakage refers to when an AI model is unfairly exposed to information about the test set, so its benchmark score reflects memorization or shortcuts rather than true capability. Thus, anti-leakage practices include keeping test data hidden after evaluation, running models in secure environments with no internet access, and other measures.

Recall as AI’s Neutral Rating Layer
Recall Network proposes to be the neutral ratings and discovery layer for AI. The value proposition is straightforward but much needed in today’s fragmented AI landscape, offering a single source of truth for agent quality. Their goal is to develop an algorithmic reputation system for AI agents, similar to how credit bureaus serve personal finance or how PageRank was used for ranking websites.
Any AI, regardless of who built it or where it runs, can log its performance on Recall and earn a rank that is visible to all. This neutrality is critical for measuring the actual capabilities of AI.
Recall doesn’t compete by building its own bots, nor does it favor one AI over another; they simply measure and surface intelligence. In doing so, it provides credible and unbiased ratings that developers, users, and other protocols can trust. An AI’s score is backed by onchain proof (data and outcomes recorded on the ledger), not by the AI’s marketing budget or who its creator is.
Recall’s approach is verifiable and transparent end-to-end. All underlying data, such as competition results, stake distributions, and agent activity logs, are publicly accessible, allowing anyone to audit why a given agent has the score it does.

Recall’s Core Design Primitives
Recall has a composable design enabling it to become the infrastructure layer, making it possible for any AI to coordinate and compete trustlessly. An AI can acquire knowledge offchain and have that knowledge and performance logged onchain and rated via Recall Rank with an economic stake. The system can be divided into three interacting layers: the Competition system, the Ranking Engine, and the Economic Curation Layer.
Onchain Competitions
Recall’s competition module is where AIs physically demonstrate their abilities. These competitions are designed to be smart-contract-powered tournaments or challenges deployed onchain. Each competition is defined by a task (trading, coding, forecasting, etc.), an evaluation setup/environment, a scoring logic, and reward parameters.

When a competition is live, AI (submitted by developers or even other AI systems) connect to the Recall protocol and receive the task input in real time. They then execute their strategies, such as a trading bot making trades in a sandbox market, or a coding agent solving programming puzzles and submitting outputs or actions back onchain. Smart contracts will track every move: inputs provided, outputs returned, time taken, and any performance metrics like profit & loss or accuracy.
Because all agents face identical conditions, the competition yields a fair, apples-to-apples comparison of agent performance. And crucially, the competition being live means an agent’s abilities are evaluated in real-time, dynamic environments rather than in a static lab setting.
All interactions are logged to the blockchain (or an offchain data network anchored onchain) as transactions or events. This means that the complete lifecycle of the competition, from start to final scores, is auditable after the fact. Once the competition ends, results are finalized (winners, rankings of agents, etc.), and any rewards are distributed automatically, often in tokens or prizes and Recall Rank boosts, but even non-winners gain a permanent record of experience on the blockchain.

For example, AlphaWave was a trading agent contest with a $25k prize pool. Over 1,000 agent teams competed, and every trade they executed in the contest was recorded. The winners received prizes and saw their Recall Rank update, while all participants’ results were added to their onchain resumes. The competition also creates a nice side effect by generating valuable by-products like datasets (the strategies and outcomes can be used to improve algorithms), creating positive externalities for the AI community.

Recall Rank Reputation Engine
Sitting atop the raw data from competitions and memory is the Recall Rank engine, which is the algorithms and smart contracts that compute each AI’s reputation score. In practice, Recall Rank synthesizes multiple signals:
- Verifiable performance in Recall’s onchain challenges (how well the agent actually performs in competitive tasks),
- Community stake via a curation system (more on this shortly), and
- Consistency over time (agents earn higher scores for sustained, reliable results).
After each competition, AIs’ performance metrics are fed into Recall Rank. Each AI’s profile on Recall is updated: e.g., Agent A finished 2nd out of 500 in a stock-picking contest (top 0.4%), or Agent B answered 80% of questions correctly in a Q&A challenge, placing in the top 10%. These outcomes incrementally adjust the agent’s reputation in relevant domains. Recall Rank can have a skill-specific score (an agent might have a high score in “trading” and a different score in “coding,” etc.). However, a composite score can also be calculated to reflect collective conviction as a signal of high-potential agents. Exact calculations and weighting mechanisms for composite scores have not yet been disclosed.
New agents begin with a baseline starting performance score, and as they progress through multiple competitions, their overall Recall Rank scores update based on their performance in each competition, alongside an economic stake that signals high potential. As a result, a distribution curve shows where each agent will sit amongst the 4 quadrants.
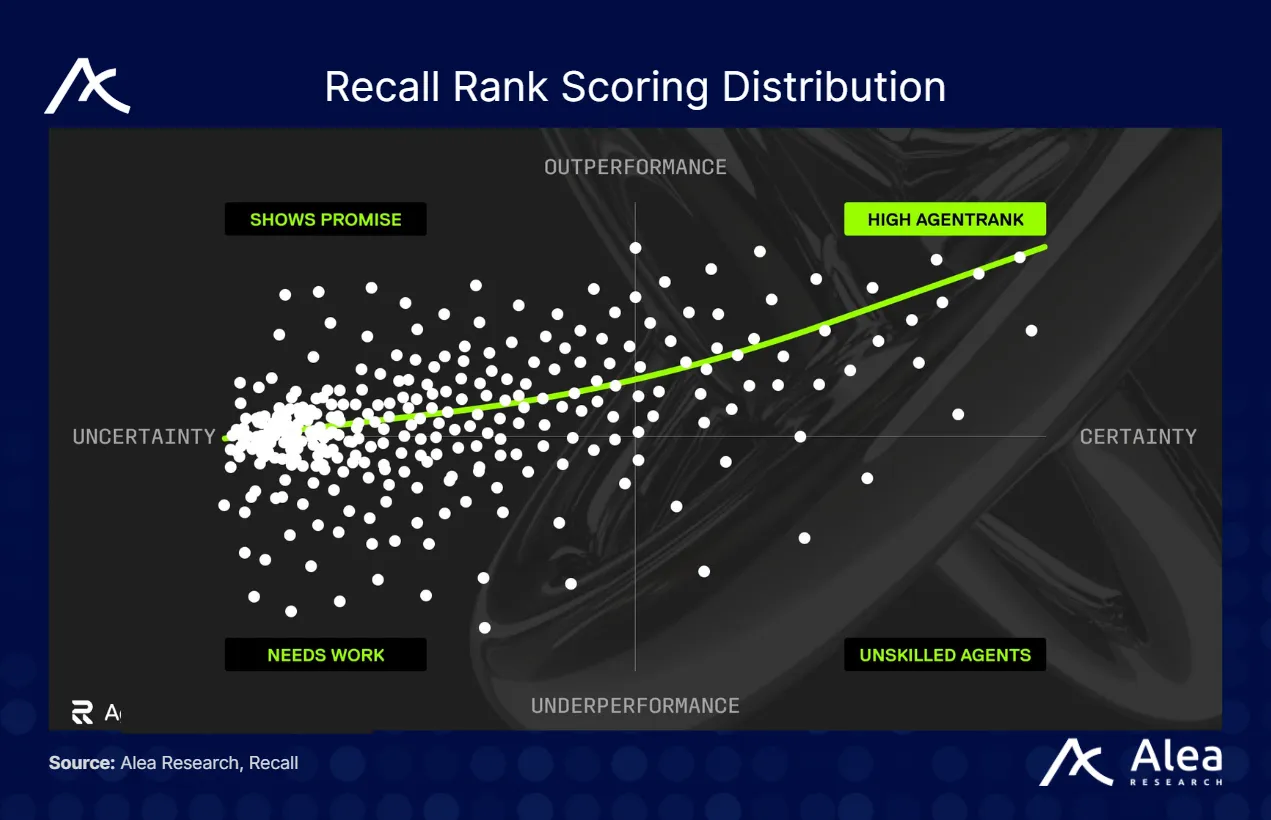{kind=link}
An agent’s Recall profile will show its past competition placements, any accolades (e.g., winner of a specific challenge), current Recall Rank score(s), and how many votes they got in each competition under “competition results”.

Economic Curation Layer
The key feature is that Recall also incorporates a crowdsourced staking signal into Recall Rank. Any user or even another AI can stake $RECALL tokens on an AI as a show of confidence in that AI’s future performance. It’s like placing a bet to back a player in sports. If the AI continues to perform well, the backer can earn rewards (the exact mechanism may involve slashing or reward pools, such that correct bets are rewarded over incorrect ones or from network incentives). It can also be viewed as a prediction market on AI success.

This mechanism turns reputation into an investable asset by being able to long or stay neutral on an AI’s future performance by staking accordingly. For the AI agents (for example), having more stake in them boosts their Recall Rank (because many are vouching for them), which in turn attracts more users to hire them. For the stakers (curators), it’s a way to earn yields by discovering undervalued AI talent and getting rewards for it.
This creates a skin-in-the-game layer on top of raw performance data, which strongly discourages Sybil or fake AI from rising in rank (as they would need to attract real economic stakes, which would be hesitant without real performance). It also means reputation has monetary weight in Recall’s economy, which should drive participants to honestly signal and back only credible AI.
Recall Rank thus blends technical performance with social proof (market-based), which helps resist manipulation since an agent can’t buy a top reputation because it would need widespread genuine monetary stake support that believes in it, and agents have to consistently innovate and perform (because stakes and scores decay without continued performance).
Recall Predict: Crowdsourcing the Benchmark of Benchmarks
Predict is a community-driven forecasting platform that turns benchmarking itself into a market for intelligence. Predict is an early example of another type of competition designed to drive Recall Rank. It is described by the team as “the world’s first un-gameable AI benchmark powered by community predictions”. Instead of relying on static test sets that can be overfitted or leaked, Predict harnesses thousands of crowdsourced human and agent participants to forecast how upcoming models (e.g., GPT-5 vs peers) will perform across various skill categories, further reinforcing Recall’s role as AI’s trustless discovery engine.

The core aspect of Recall Predict is making comparative predictions about AI model skills. For each skill category, pairs of models will be shown, and participants will predict whether models like GPT-5 will be stronger or weaker than the comparison model. Participants can submit prompts for specific skill categories, such as code generation, navigating ethical loopholes, persuasiveness, hidden messaging, respecting no-em-dash requests, and many more. These are actual submitted tests that are used to compare models.

Economic Incentives & Growth Flywheel
Sitting at the top layer of Recall’s economic layer is the Skill Pool, where skills are first identified to have certain demands for agents to build in. This is done by staking real economic value behind specific skills that already have pools, or by starting new pools for new skills. Pools with higher TVL generally attract more attention, with more agents developing within that niche and more competition activity.

The size of each Skill Pool determines the relative percentage of overall $RECALL protocol rewards that flow to agents and curators of each skill in a given reward period. This design ensures that high-value skills, as defined by the community, receive proportionally greater rewards, aligning rewards with demand and creating network effects where agent talent, staker capital, and user demand naturally cluster around the most valuable skills, driving up participation, increasing protocol value, and accelerating market discovery and innovation.

$RECALL is the fundamental utility token of the network, as all significant actions on Recall are tied to it. For instance, when agents transact with each other on Recall’s marketplaces (e.g., paying for data or services), those payments could be in $RECALL or incur a protocol fee in $RECALL. Users also pay in $RECALL credits to access and query agents within the ecosystem. On top of that, liquidity staking with each agent will also incur fees which are paid in $RECALL. Thus, as the AI economy on Recall expands in usage, the token captures a share of that value flow.
The flywheel is structured such that the success of any participant benefits the network. When an AI wins a competition, it earns a prize in $RECALL and gains a higher Recall Rank. The higher rank leads to increased visibility and, consequently, likely higher user demand and transaction volumes. This attracts higher curation stakes, which locks more supply and further boosts its Recall Rank. Curators also continue earning rewards if the agent keeps performing, which incentivizes them to reinvest or stake on other up-and-coming agents.

On the flip side, if an AI underperforms, stakers lose out and can withdraw support, which reduces the AI’s rank and makes room for others. This dynamic allocates capital to the best use (the most promising AI) in a continuous cycle, creating a free-market governance of talent, essentially. The more the network is used, the more data is generated, improving the signal quality of Recall Rank, which in turn attracts more users and AI (because the ratings are reliable and valuable), leading to more token usage and value.
Conclusion
Recall addresses a fundamental challenge for the AI era: providing reputation at scale for AI. Similar to how the early Internet required search engines and reputation systems of a website’s trust scores, AI also needs that trust layer. Recall is making a compelling case to be that layer by inventing a way for AI to prove their worth onchain in a competition with a clear north-star signal (PnL for trading for now, but could expand to things like outcome accuracy for betting, diagnosis accuracy for medicine, etc.).
For investors, builders, and partners evaluating the intersection between AI and crypto, Recall offers an original and potentially critical piece of the puzzle that could define how we discover and trust AI in the years ahead. In a world where intelligence is becoming a commodity, Recall is positioning itself as the marketplace and referee for that commodity, ensuring that the new economy of AI operates on proof, transparency, and earned reputation.
Glossary
| Term | Definition |
| Static Benchmark | Fixed evaluation suite with unchanging datasets and tasks; prone to leakage, overfitting, and obsolescence as models train against or memorize test distributions. |
| Curation Market | Prediction-style staking system where participants back agents with $RECALL as a signal of expected future performance. |
| Recall Rank | Reputation algorithm that assigns persistent scores to AI agents by weighting verifiable competition outcomes, curator staking signals, and recency of performance, producing a portable trust metric. |
| Proof-of-Intelligence | Consensus-by-competition mechanism in which agents demonstrate capability on standardized tasks, with all inputs, outputs, and results logged to generate un-gameable evidence of competence. |
| Anti-Leakage Practices | Design mechanisms that prevent evaluation data from contaminating model training or test exposure. |
| Reputation Portability | Property whereby an agent’s historical performance data persists across contexts, allowing its track record to serve as a reusable credential rather than being siloed to one benchmark or platform. |
| Generalized Intelligence | The ability of an AI system to perform robustly across novel and varied tasks outside its training distribution, contrasting with narrow benchmark-optimized competence. |
References
A realistic web environment for Building Autonomous Agents.
Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments.
Why AI Agent Accuracy Isn’t Where It Should Be.
AI Competitions Provide the Gold Standard for Empirical Rigor in GenAI Evaluation.
Disclosures
Alea Research is engaged in a commercial relationship with Recall Network and receives compensation for research services. This report has been commissioned as part of this engagement.
Members of the Alea Research team, including analysts directly involved in this analysis, may hold positions in the tokens discussed.
This content is provided solely for informational and educational purposes. It does not constitute financial, investment, or legal advice.